

Understanding Dependency Chains in Outages
When a single component fails inside a distributed system, the effects rarely stay local. A brief interruption, an unresponsive endpoint or a delayed cronjob can trigger visible symptoms in completely different parts of the architecture. A slow UI, a stalled checkout flow or growing queues often appear far from the actual failure point.
The real challenge is not detecting that something is wrong. It is identifying where the issue originated and which parts of the system are affected. Logs and dashboards show isolated pieces of information, but they do not reveal the full dependency chain. Domain Tree fills this gap by visualizing the failure at its source and showing how it spreads across the system. Instead of chasing surface symptoms, teams can see the impact path instantly and focus on the true root cause.
Real-Time Dependency Visibility with Domain Tree
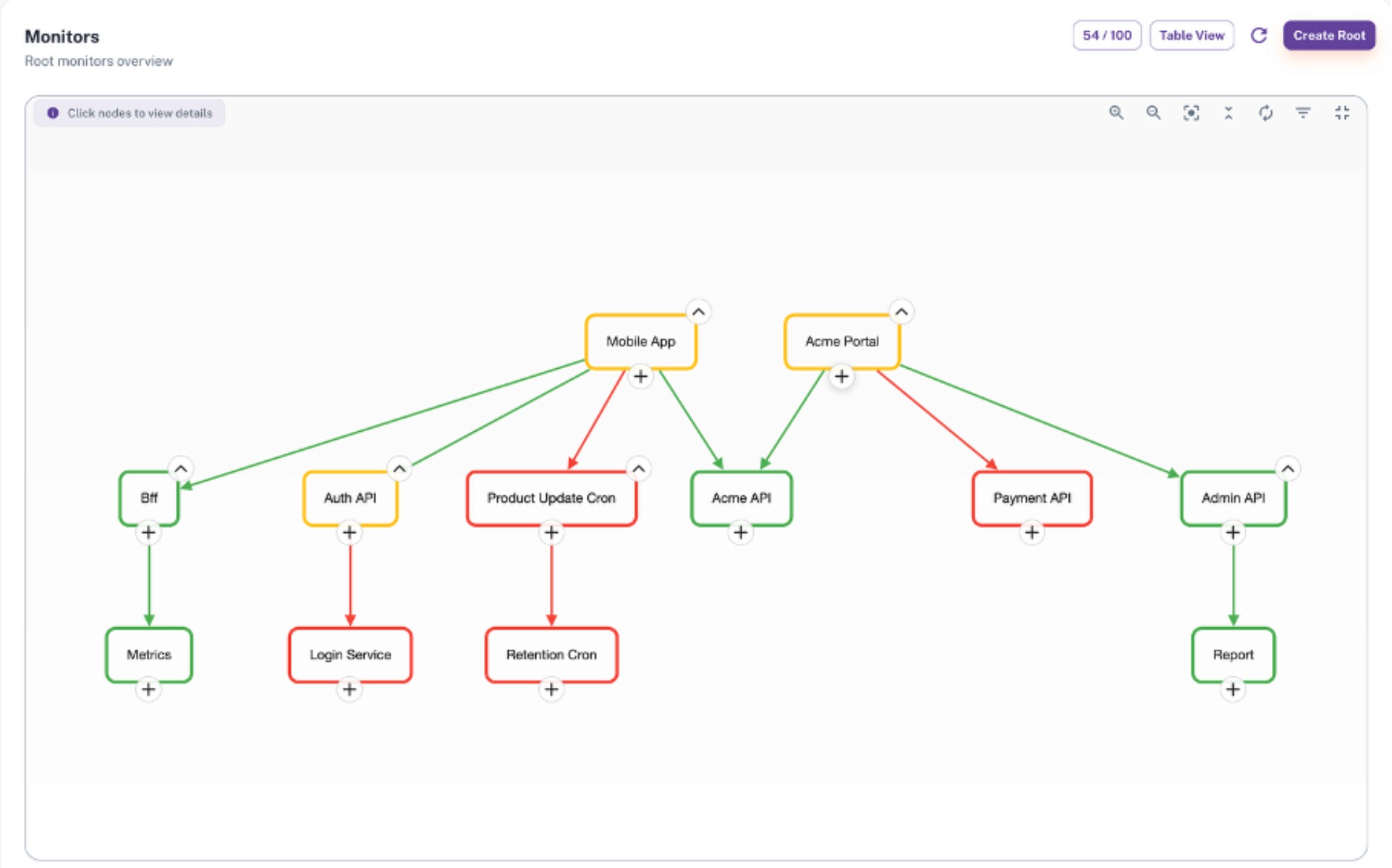
Domain Tree brings all HTTP endpoints, push-based services, cronjobs and internal workers together in a single hierarchical model. Each node shows not only its own status but also whether its health is degrading because something it depends on has failed.
Green indicates that both the node and its dependencies are fully healthy.
Yellow means the node is reachable, yet a dependent component is failing, creating a degraded state.
Red shows that the node itself is down or unreachable.
The yellow state is where most monitoring tools fall short. A node can respond successfully while still behaving inconsistently because an upstream component has stopped working. Domain Tree makes this indirect degradation visible instead of hiding it behind isolated checks.
This clarity comes from the status propagation model. When a leaf node goes down, the degradation moves upward to the root it relies on. If that root also becomes unresponsive, it is marked down. When the leaf recovers, the entire chain returns to a healthy state automatically.
As a result, teams can immediately understand both where the issue originated and how far its effects extend. For example, if the Inventory Service becomes unreachable, the Order Service may turn yellow and the UI may slow down because stock data cannot be retrieved. Domain Tree displays this chain instantly and removes guesswork.
Unified Model for All Monitoring Methods
Different components expose their health in different ways. Some respond to HTTP checks, others send periodic push signals, and some rely on scheduled cronjobs or background workers. This diversity often fragments monitoring and makes it difficult to understand the system as a whole.
Domain Tree brings these methods together under a single, consistent model. Regardless of how a node reports its status, it becomes part of the same hierarchy and follows the same propagation rules.
For example, if a cronjob stops sending signals, the node first enters a pending state and then transitions to down when the timeout expires. Any nodes depending on it immediately shift into a degraded state. Instead of misdiagnosing the issue as an API failure, teams can see that the root cause is an upstream cronjob outage.
This unified context dramatically reduces investigation time and removes uncertainty during incidents.
Preserving Context in Distributed Systems
In distributed environments, the difficulty is often not the failure itself but the cascade of effects it creates. A single node going down can produce misleading symptoms across multiple layers.
Domain Tree prevents this loss of context by representing nodes as interconnected elements rather than isolated checks. A degraded or down state is not just a signal. It directly reflects where the failure sits in the dependency structure.
This eliminates unnecessary restarts, log searches and blind troubleshooting. Teams quickly identify the correct component to investigate, and new team members can understand the architecture simply by observing the relationships between nodes.
With this structure, operational decisions become faster and more accurate.
Why Domain Tree Matters
Most monitoring tools can tell you if a service is up or down, but they do not explain why it is in that state or how the issue impacts the rest of the system.
Domain Tree provides that missing context instantly by:
• exposing dependencies
• mapping the propagation chain
• clarifying how failures influence other components
The result is:
• fewer false alarms
• faster root-cause analysis
• more predictable operations
Domain Tree does not prevent outages, but it transforms the way teams understand them. Investigations become more focused, decisions become more confident and the overall architecture becomes easier to reason about.



